Integration Guide
This document outlines a preliminary set of options available for integrating the AlumnIQ Signature Events Service with your constituent database.
We have mechanisms in place to support static and web services integration endpoints. These mechanisms are all customizable to adapt to your specific integration needs and in a manner that can be supported by your staff efficiently and effectively. We do not presume that any campus has web services established for this purpose, but will work with your team to implement a solution that moves data efficiently between our two systems in a manner you’re comfortable with.
This document is intended to generally outline what is possible. What we will jointly agree to use depends entirely on institutional comfort level and desired capabilities
Constituent Identification
The system supports several methods for constituent identification:
- Authenticated – the registrant logs in using known credentials, which then conveys to our system the constituent identifier used to retrieve additional constituent profile data. Shibboleth and OAuth are currently supported.
- Lookup – whether this hits a remote web service or one we wrap around a static local warehouse, the constituent enters a few pieces of information and we’ll find a matching constituent record in the dataset. If the match is good, everybody is happier. This is 95+% effective provided that the data set contains at minimum a preferred class year (degree information is also welcome) in addition to a name.
- Post - match – registrants enter all name and contact information. On a periodic basis these records are run through a matching program (on your end) to try to link them to a constituent record.
All of our clients use a combination of these mechanisms. When there’s a defined, closely-held constituency (faculty for example), we have typically used the authenticated approach. The lookup approach is good when we can present the candidate matches to the registrant for their review – they do a good job of identifying themselves based on a few indicators. The method that only works well if you have good processes (software) or a few people to put on it is post-match.
Most clients use a combination of 2 and 3, as presenting a login for your registration process does appear as a barrier to folks who don’t have/know credentials (even if there’s an obvious way around it). Registrants are strongly encouraged to go through the self-lookup process. Only after failing to find a match will they be permitted to register without a match to xid (your key identifier); admin processes will then take over after they’ve registered.
- Authenticated
If you do have a centrally available login service for all of the constituencies you expect to attend your events and it happens to be Shibboleth or OAuth, we will gladly tie in to it. After authenticating, we’ll take that xid (your primary institutional identifier) and call a web service (provided by you) to feed us additional constituent information (address, degrees, etc.). That web service could alternatively be designed to hit a local (to the registration system) warehouse of the same data.
- Lookup
Registrants will be asked to input enough search data (last name, first initial, and sometimes preferred class year) for us to find them in a data warehouse you’ll provide to us. Under the surface we’ll then establish a hard link between that warehouse record (authoritative identity information) and the registration record (only as true as they enter it). We’ll prepopulate the name, relationship-to-school checkboxes, and class year if applicable to speed registration along but will not expose any contact information publicly. This is by far the most popular and easiest approach to implement.
- Post-Match
For those who don’t match to a known constituent record, they’ll be permitted to register but will end up in a queue for admin review. This review process will involve an actual person looking up the constituent in your CRM system, creating a record if necessary, and applying the xid to the registrant’s record if appropriate. Registrants who are not found and will not be created in your CRM system can have a flag set on their record to ignore the xid field.
With a combination of these processes in place, we can ensure that the maximum possible number of constituents are matched to their xid as early in the process as possible for enhanced reporting during the event and easy import after the event is over and the data has been scrubbed.
Important Considerations for Matching
Matching your constituents early in the process allows us to activate a number of features that are helpful:
- conditional visibility of events during the registration process
- real time notifications for gift officers/prospect managers upon registration
- weekly prospect attendee reports for gift officers/prospect managers
- real time notifications for gift officers/prospect managers when the individual(s) check(s) in
Furthermore, linking registrant data to a local warehouse (either preloaded or populated as a live cache from your web service data) allows us to join that data in to reports. This contextual/background info is really, really helpful to event organizers. The warehouse typically contains contact info as well as prospect ratings, region assignments, school/degree information, and similar info that adds value to particularly for any type of summary reporting for leadership.
- Event reports
- Scheduled reports
- General attendance reports
This is why we encourage you to lean in to the idea of allowing at minimum self match so all of these features are possible and available.
Address updates for Matched registrants
Address collection is done at the end of the registration process during the checkout step. Your option here is whether or not we collect addresses for $0 due registrants – we recommend against it but understand the business value to capturing it regardless.
All address data is timestamped and used in a comparative report to identify mismatches/updates relative to the address info in the data warehouse. You have the option of pulling those mismatches on demand (via API or manual report retrieval) or waiting until your event is over and updating at that point. We generally recommend taking them in as early as possible.
Registration Management
There are always attendees who register via paper or over the phone. The administrative interface is designed to first search both registration and warehoused data for the constituent prior to initializing a new registration record. This will ensure that we are always working from a known constituent’s record as much as possible and reduce if not eliminate the opportunity for duplicate record creation.
Reporting and Monitoring
There will always be a few who manage to evade our lookup-and-link methods. The registration system will incorporate a report of all those who do not yet have an xid on their registration record so we can flag them as non-constituents (rare) or connect them (via search + modification).
The end result is that we have the cleanest possible data set, ready for any subsequent data exchange scenarios for registration, badge printing, reporting, and/or external feed operations.
In addition, we’ll be closely watching all API calls to and from the warehouse to ensure they are secure, performant, and returning the expected data.
Registration data Feed
We ordinarily recommend that attendance data not get pushed to external systems until after the reunion events have occurred so that the data set is as stable as possible. As we all know, people add and drop event participation quite frequently in the weeks leading up to the weekend. If you do consume and store it nightly, we recommend you purge and reload from scratch.
Once reunion is over we’ll batch the attendee data and send it to your system (probably just in a spreadsheet but again you can pull via API anytime you wish) so that you have a historical record of attendance at reunion. We are open to discussing sending registrant activity notifications up to your system as they happen if a web service ever becomes available.
The Data Warehouse
The registration system maintains a warehouse of constituent data for reporting purposes. This data is either batch loaded prior to the registration window opening or added a record at a time as people register. The mechanism is determined by the selected integration model and whether real time web services are available.
While the warehouse is fairly similar across clients, we do allow for some variability across schools so that it contains exactly what you need it to. The actual field names (core fields aside) will be determined by the team building the warehouse for us from your CRM data.
Not all of these are necessary for the operations of the system, but we know from past experience that many of the end users like to see certain fields in reports that assist the organization’s fundraisers and other operations staff outside of reunion leadership. We’ll refine this list during implementation planning.
If you do provide a flat file, we request that it be a CSV file with all fields quoted to avoid any import failures.
As far as warehouse transmission, we prefer to use Amazon S3 for the transfer. We’ll issue you an access key and access token to gain access to a private bucket. Command line and GUI tools are freely available to assist in the movement of the file(s) to S3. The frequency of refresh does not need to be daily – many of our clients offer up a file during the build so we can test it, just prior to launch (with final revisions), at some midpoint during registration, and again a couple days prior to your event. We mention that only to save you from building an elaborate automatic refresh mechanism if you don’t already have one. Also, if you wish to sign and encrypt the file with PGP just to add another layer of protection we’re happy to share keys to do so.
CORE WAREHOUSE (all fields required, even if not populated)
Three fields are absolutely required for all records in your feed: xid, firstname, and lastname. All others are permitted to be blank.
| Field | Purpose |
|---|---|
| xid | Your primary constituent identifier |
| xid2 | Your secondary constituent identifier (if applicable) |
| prefix | |
| firstname | |
| middlename | |
| lastname | |
| maidenname | |
| badgenameoverride | nickname/informal first for name tag |
| badgelastnameoverride | |
| badgeannotation | This is the degree/class string that appears on the name tag. Some include parent years, others do not. This should be composed and formatted per your institutional standards. "’99 ’37P" and "’04 ’05G" are examples from a school who sticks letters on the end. Yours may be before, after, or some other remix of the concept. |
| address1 | |
| address2 | |
| city | |
| state | |
| postalcode | |
| nation | properly formatted for your payment gateway |
| emailaddress | |
| homephonenumber | All digits, no formatting |
| mobilephonenumber | All digits, no formatting |
| prefclassyear | The primary preferred class year for this individual |
| prefschool | The primary preferred school association for this individual (spelled out) |
| prefdegree | |
| prefdegreetype | U = undergraduate, G = graduate |
| isalumnus | 0/1 |
| isgradalumnus | 0/1 |
| isparentofstudent | 0/1 |
| isfamilyofstudent | 0/1 |
| isfaculty | 0/1 |
| isstaff | 0/1 |
| isstudent | 0/1 |
| isgradstudent | 0/1 |
| prospectmanager | |
| prospectmanageremail | |
| ismember | 0/1 (if your alumni assoc is membership-driven, is this a paid/formal member entitled to special benefits/recognition?) |
| membertype | literal string describing membership type |
| AND THEN | Any additional fields you will find useful to reflect through us. Please only append them to the core – do not position them elsewhere. |
As far as write-back goes, we’ll await direction on where that information will be stored and what additional attributes need to be attached to that activity when it happens.
The AlumnIQ API
The AlumnIQ API is REST-based and can accept and return data in XML or JSON (preferred) format. There are several endpoints available for your immediate use, and we are open to ideas for additional endpoints as conditions warrant and needs dictate.
ER Diagram
You’ll have an easier time understanding which endpoints to pull from if you understand the object model providing data to them.
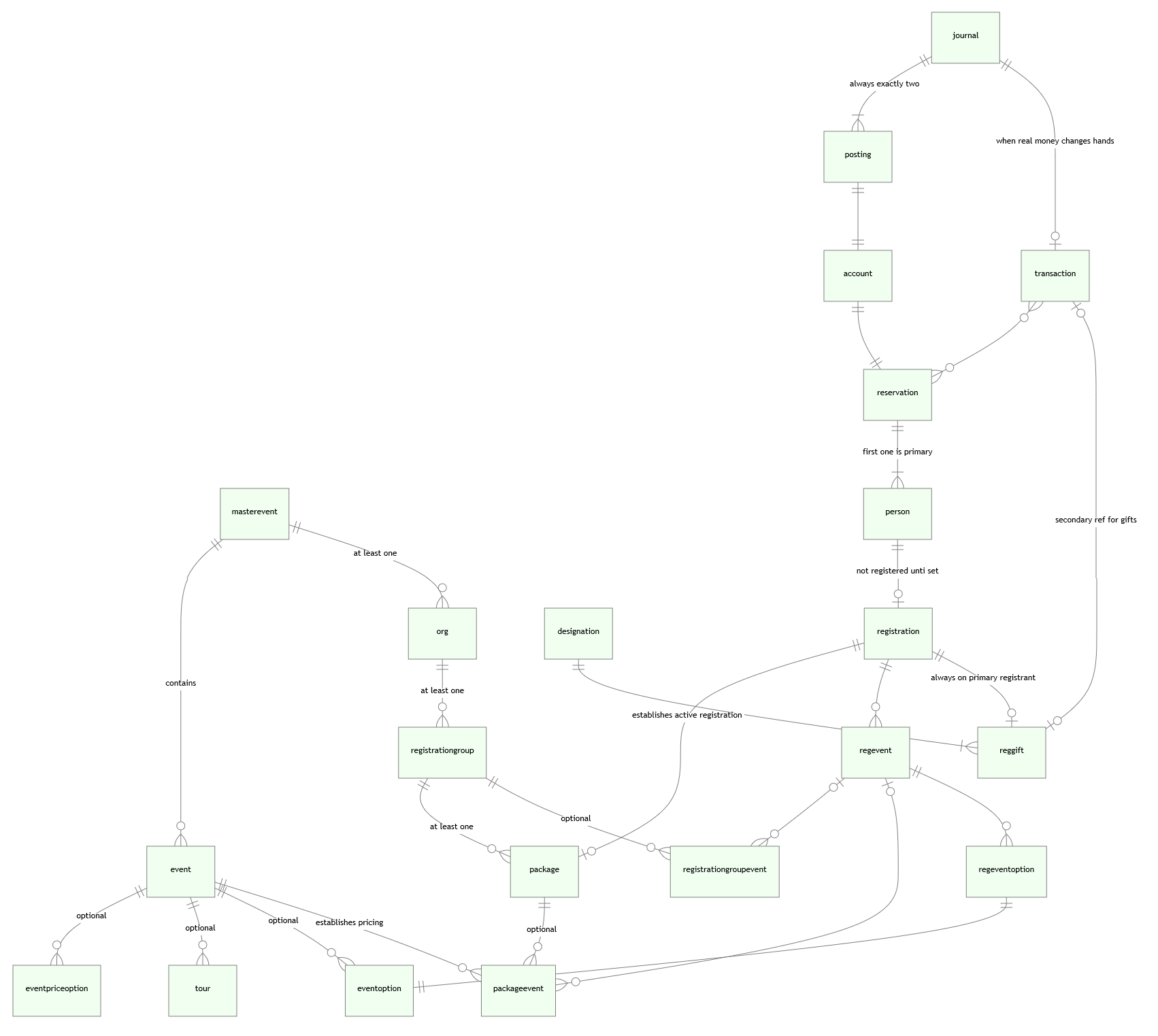
Basics
Your web service endpoint will be at https://{cust}.events.alumniq.com/api/index.cfm
API Keys
You have two options:
AlumnIQ Platform Customers: you can use your AlumnIQ Platform API key to access and exercise all AlumnIQ Signature Events service API resources or a service-specific one generated on the Security screen of the signature events service.
AlumnIQ Signature Events Customers: you can use an API key generated on the Security screen of the admin console.
All endpoints listed below should be prefixed with the endpoint url appropriate for your environment following the pattern above.
Metadata
/masterevents – a feed of mastereventIDs which you’ll need to pass along on many of the other API calls so that you’re pulling the right segment of data.
/events/ - (req: mastereventid) a feed of event metadata (name, dates/times, tags, location, fees, etc.) that can be read, cached, transformed, and reused to populate event data on your website. For obvious reasons we strongly recommend doing your own caching of the data as it doesn’t change much and your site visitors surely don’t need to wait for round trip API calls just to see a schedule of events.
People
/people – (req: mastereventid, opt: registrationdate) everybody registered regardless of what they’re registered for. A great feed for bio updates, extraction for an email list, or temporary storage. We recommend purging your local copy and reloading daily if that’s your plan – people cancel all the time.
/person/{personid} – bio data for one individual registrant. You can also POST to that same endpoint to update (if passed) each or any of: xid, prefclassyear, badgenameoverride, badgelastnameoverride, badgeannotation, donormeta, and volunteermeta. This is a convenient way for you to do your own constituent matching algo and update our end with that new xid data.
/cancellations – (req: mastereventid, opt: canceldate) fairly self explanatory
Events/Participation
/events/{eventid}/attendees – get an array of people registered for a given event, indicating whether or not they attended.
Person-Event Combo
/gridreference – (req: mastereventid) – this gives you the column mappings to understand and interpret the response from the grid endpoint
/grid – (req:mastereventid) – people down the left, columns for each event indicating participation (registered or attended if true) at each intersection. A basic set of personal info is included; we expect you’ll hit the /people endpoints to get more if needed.
Gifts
/gifts - (required: datePaid=yyyy-mm-dd) - all gifts, regardless of event/masterevent, paid on the requested date.